How to save a perfectly-scraped webpage into DEVONthink using IFTTT, Diffbot, Hazel, & several command line tools
DEVONthink is a key piece of software for me on my Mac. In particular, I use it to store copies of webpages that I run across that I want students to read or that I want to refer back to for teaching, or for writing, or for my own use. Now, it’s very easy to get webpages into DEVONthink by using the browser extensions that come with the software. You click on the extension, & you get a small window:
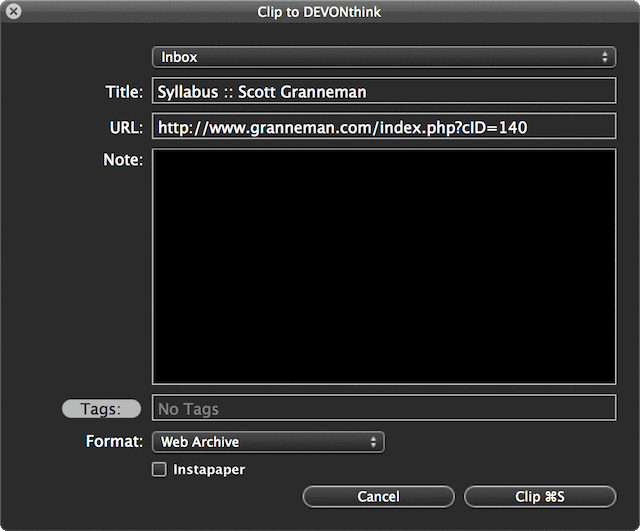
See the Format menu? When you click it, you get several choices:
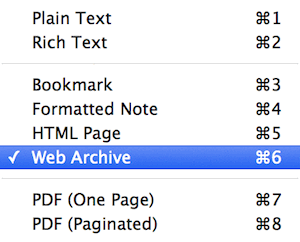
This is great, as is the checkbox for Instapaper, which runs the webpage through that awesome service & gives you results with just the featured content & none of the crap. But even with Instapaper, these results are not perfect, at least for me.
Here’s my problem: I want a webpage so that I can see images & hyperlinks & other stuff that only comes with the Web. I like PDFs, but not when I can just have good ol’ HTML to deal with. But if I choose the HTML Page or Web Archive options, then I get a bunch of junk I don’t want, like ads & extraneous content. If I check the box next to Instapaper, I get less junk, but I lose a lot of control over what gets selected & what doesn’t get selected, & the original URL of the webpage, along with a lot of other important metadata, gets stripped away by Instapaper. In other words, I want this:
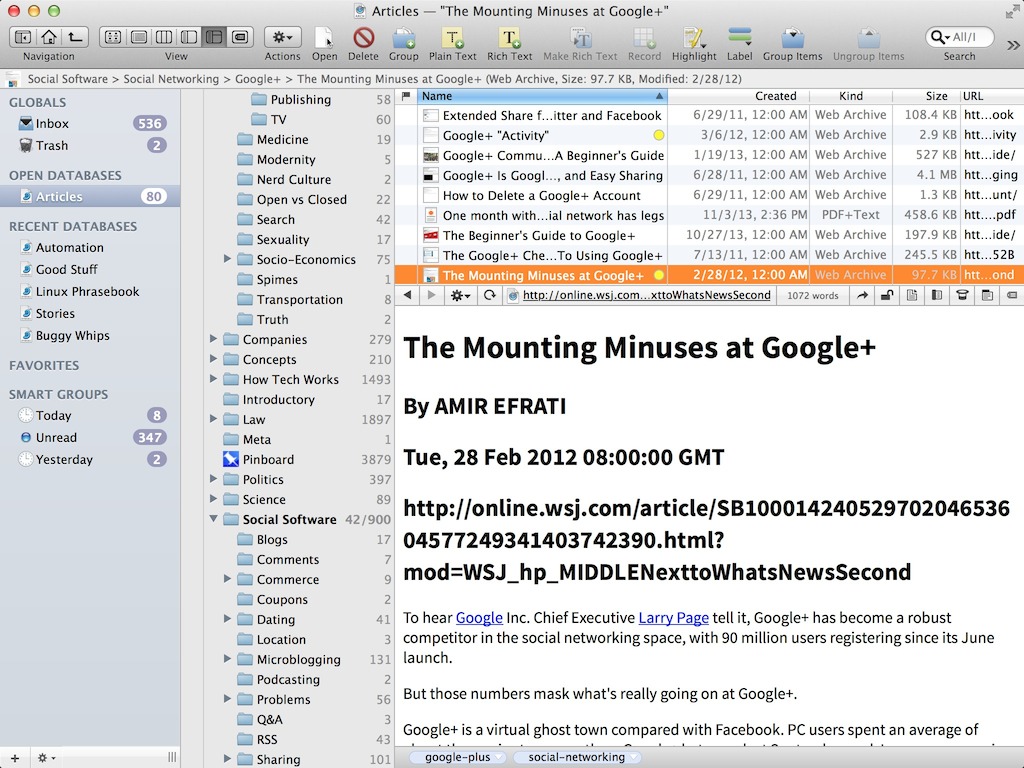
See? Neat & clean, with the title of the Web article at the top as an H1, & then the author, date of publication, & URL below, all H2s in the HTML, & finally the content & nothing else.
Yes, I know this is picky, but it’s what I really want. So I set out to create it over several months, & I finally got it all figured out & set up & working this summer. After testing it for months to verify that it works well, I am now ready to unveil this process to you, the readers of Chainsaw on a Tire Swing.
Before I dig in to the details, let me give you the 20,000-foot summary of the process. It might seem complicated, & I guess it kinda is, but it’s not that bad if you go through it step by step, & it does work beautifully. I’m going to mention several services in this introduction that you might not have heard of. Don’t worry; I’ll explain everything below.
- Send an email to the IFTTT (If This Then That) service which contains the URL of the webpage at the top of the message.
- IFTTT saves the email as a file in a specific folder in your Dropbox.
- Hazel on your Mac notices the new file in the folder & runs a shell script.
- The shell script grabs the URL out of the file & sends a request to the Diffbot service, which saves the result to the
/tmpdirectory as a webpage. - The shell script converts that resulting webpage to a
.webarchivefile & saves it to DEVONthink’s Inbox folder, where it is automatically imported into DEVONthink.
Got that? OK, let’s set it all up!
Table of Contents
Diffbot
I love Diffbot. I really do. It’s the best service of its type I’ve seen, the price is right (free for the 1st 10,000 requests each month!), & the support I’ve received when I’ve had questions or issues has been top-notch. So what’s it do?
Simple. It’s a scraper: you send a request to Diffbot using its API, you get back the data from a webpage, shorn of all the junk. It’s like Safari’s Reader feature, but available programmatically. Here’s an example.
First, a blog post at The Atlantic’s website, as it appears in a browser:
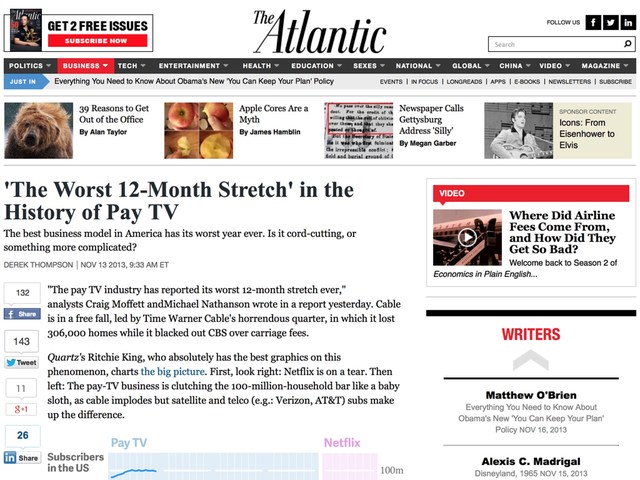
Next, the same post after it’s been passed through Diffbot & brought into DEVONthink:

A bit cleaner, eh?1
So, here’s what you need to do: go to Diffbot’s website, create an account, find out your Diffbot Developer Token (you’ll need it for the shell script), & then come back here.
Dropbox
You don’t have to create these folders exactly where I specify, but if you change their locations, you’re going to need to edit the shell script that’s coming up.
Create a folder at root of your Dropbox named Incoming. Inside the Incoming folder, create another folder named DEVONthink. Your folder structure should therefore look like this: ~/Dropbox/Incoming/DEVONthink
IFTTT
If you don’t already have an account with If This Then That (IFTTT), go get yourself one! It’s a free service that lets you tie together online services so that when one event happens at one service, then something happens as a response. For example, every time you post a picture to Facebook, a copy is placed in a Dropbox folder, or every time a particular RSS feed is published, it’s scanned by IFTTT, & if certain words are in the title, that post is emailed to you. It’s such a great service that I’d pay for it if I had to.
To use it with my process here, create an account at IFTTT if you don’t already have one, log in to IFTTT, & activate the Dropbox & Email channels.
Now go to My Recipes & click Create A Recipe. Here’s what you’re going to fill in:
- Description:
App emails IFTTT a URL, which gets saved as a text file - Trigger: Send IFTTT an email from your email address with a tag of
dt(for DEVONthink, get it?). - Action: Create a text file in Dropbox
- Dropbox folder path:
Incoming/DEVONthink - File name:
Subject - Content:
Body
- Dropbox folder path:
Save it, & you’re good to go.
So here’s what happens: you find a webpage that you want to capture in DEVONthink. You email the link to yourself, with the URL as the first line of the body of the email (you can have other stuff in the email, like your signature, but it will be ignored by the upcoming shell script). As for the subject, it really doesn’t matter—it can be words, it can be a URL as well, it can be nothing—as long as you have #dt in it (I always put it at the end because that’s easy).
When the email arrives at IFTTT, it is saved as a text file in the specified Dropbox folder. The subject of your email becomes the name of the file, & the body of your email becomes the contents of the file.
We now have a place in Dropbox for incoming text files containing URLs that we want to use, & a method for getting those text files into Dropbox: emailing IFTTT. But what do we do with those text files once they’re in there? Time for some shell scripting!
Needed command line software
The shell script I’m going to provide has several requirements:
gecho(the GNU version ofecho)gsed(the GNU version ofsed)dos2unix(converts text files between Windows & UNIX/Mac OS X formats)jsonpp(prettifies JSON files)terminal-notifier(send Mac OS X notifications)webarchiver(create Safari .webarchive files)
All of those but one are available through Homebrew, so if you haven’t already installed that, you’ll need to do so.
Once you have Homebrew up & running, run this command (it’s not obvious, but coreutils takes care of gecho—& a whole lot more besides):
$ brew install coreutils gnu-sed dos2unix jsonpp terminal-notifier
Update from 2016-06-03: Homebrew now includes
webarchiver, so just add that to the line above. You do not need to download the code & compile it using Xcode, unless you really want to.
If you use MacPorts (who uses that anymore?), you can download webarchiver pretty easily, according to the developer:
$ sudo port install webarchiver
I don’t use MacPorts, so I have no idea how effectively this is. Instead, you’re going to have download the code & compile it using Xcode.
I went to the GitHub page for the webarchiver project, got a copy of the code (don’t download the release, as that’s 0.3, which is ancient & won’t compile on newer Macs; instead, get the latest code, which is version 0.5), & double-clicked on webarchiver.xcodeproj to open the project in Xcode. Once in Xcode, I went to Product > Build, which successfully compiled the code, leaving the binary in /Users/scott/Library/Developer/Xcode/DerivedData/webarchiver-dreeepqxmdlkgieggztknlbwsula/Build/Products/Debug/webarchiver. Obviously, your path under DerivedData will be different2. I then moved the webarchiver binary to /usr/bin.
Once you’ve moved webarchiver to its new home, test it:
$ webarchiver
webarchiver 0.5
Usage: webarchiver -url URL -output FILE
Example: webarchiver -url http://www.google.com -output google.webarchive
-url http:// or path to local file
-output File to write webarchive to
Updates can be found at https://github.com/newzealandpaul/webarchiver/If you see that output, you’re good to go.
The shell script
Place the shell script you see below in your ~/bin directory. I named it conv_to_webarchive.sh (you can use your own, but if you change the name, you’ll need to also change the instructions for Hazel that are coming up). I’ve commented the heck out of it, so I hope that helps explain what each step is doing.
#!/bin/bash
#===============================================================================
# FILE: conv_to_webarchive.sh
# USAGE: Automatic with Hazel
# DESCRIPTION: Uses diffbot to download essential info about an article
# & webarchiver to convert it to a .webarchive file
# AUTHOR: Scott Granneman (RSG), scott@chainsawonatireswing.com
# COMPANY: Chainsaw On A Tire Swing
# VERSION: 0.4
# CREATED: 06/22/2013 13:50:23 CDT
# REVISION: 11/17/2013 15:20:43 CDT
#===============================================================================
#####
####
### Variables
##
#
incoming_dir="/Users/scott/Dropbox/Incoming/DEVONthink"
devonthink_dir="/Users/scott/Library/Application Support/DEVONthink Pro 2/Inbox"
fail_safe_dir="/Users/scott/Desktop"
diffbot_token="tm3wnis0wa1irfvgl4ulmqi3iiu0sx1f"
#####
####
### Grab webpages
##
#
# Test to see if the necessary directories exist
if [ -e "$incoming_dir" ] && [ -e "$devonthink_dir" ] ; then
# Set IFS to split on newlines, not spaces, but first save old IFS
# See http://unix.stackexchange.com/questions/9496/looping-through-files-with-spaces-in-the-names
SAVEIFS=$IFS
IFS=$'\n'
# If you can cd to the Incoming/DEVONthink directory, run everything else
if cd $incoming_dir ; then
# For every file containing a URL in the Incoming/DEVONthink directory
for i in $(ls *)
do
# If it’s not empty, process it;
# if it IS empty, move it so Diffbot doesn’t keep trying forever
if [[ -s $i ]] ; then
# Check if it’s a Windows-formatted file; if it is, convert it to UNIX
if [ $(grep -c $'\r$' "$i") \> 0 ] ; then
terminal-notifier -message "$1 is a Windows file, so convert it" -title "Windows File Found"
/usr/local/bin/dos2unix "$1"
fi
# Delete any blank lines
# Note: will only work with UNIX line endings, hence the previous conversion by Hazel
/usr/local/bin/gsed '/^$/d' "$i" > "$i".out
mv "$i".out "$i"
# Read the file to get the URL
# I use head instead of cat because the file usually comes in via email,
# & I’m too lazy when composing to leave off my email sig
url=$(head -n 1 $i)
/usr/local/bin/gecho -e "\nURL in the file is $url"
# URL encode the, uh, URL
encoded_url=$(python -c "import sys, urllib as ul; print ul.quote_plus(sys.argv[1])" $url)
/usr/local/bin/gecho -e "\nEncoded URL is $encoded_url"
# Grab JSON-formatted article & data from Diffbot,
# clean up JSON, & write results to file
if curl "http://www.diffbot.com/api/article?token=$diffbot_token&url=$encoded_url&html&timeout=20000" | /usr/local/bin/jsonpp > /tmp/results.json ; then
# Pull out article’s name
article_title=$(grep -m 1 '"title":' /tmp/results.json | /usr/local/bin/gsed 's/ "title": "//' | /usr/local/bin/gsed 's/",$//' | /usr/local/bin/gsed 's:\\\/:-:g' | /usr/local/bin/gsed 's://:-:g' | /usr/local/bin/gsed 's/\\"/"/g' | /usr/local/bin/gsed -f /Users/scott/bin/conv_to_webarchive.sed)
/usr/local/bin/gecho -e "\nArticle Title is $article_title"
# If $article_title is empty, move it so Diffbot doesn’t keep trying forever;
# if it’s not empty, continue processing it
if [[ -z $article_title ]] ; then
# If $article_title is empty, move it!
mv $i $fail_safe_dir
terminal-notifier -message "Diffbot could not parse title in $i" -title "Problem with Diffbot"
else
# If results.json can be renamed, continue processing;
# if it can’t be renamed, move it!
if mv /tmp/results.json /tmp/"$article_title".json ; then
# Pull out article’s other metadata
article_author=$(grep -m 1 '"author":' /tmp/"$article_title".json | /usr/local/bin/gsed 's/ "author": "//' | /usr/local/bin/gsed 's/",$//' | /usr/local/bin/gsed -f /Users/scott/bin/conv_to_webarchive.sed)
/usr/local/bin/gecho -e "\nArticle Author is $article_author"
article_date=$(grep '"date":' /tmp/"$article_title".json | /usr/local/bin/gsed 's/ "date": "//' | /usr/local/bin/gsed 's/",$//' | /usr/local/bin/gsed -f /Users/scott/bin/conv_to_webarchive.sed)
/usr/local/bin/gecho -e "\nArticle Date is $article_date"
article_url=$(grep '"url":' /tmp/"$article_title".json | /usr/local/bin/gsed 's/ "url": "//' | /usr/local/bin/gsed 's/",$//' | /usr/local/bin/gsed 's/\\//g' | /usr/local/bin/gsed 's/"$//')
/usr/local/bin/gecho -e "\nArticle URL is $article_url"
# Write HTML to file
# Remove JSON stuff, fix Unicode, then remove \n, \t, & \
grep '"html":' /tmp/"$article_title".json | /usr/local/bin/gsed 's/ "html": "//' | /usr/local/bin/gsed 's/",$//' | /usr/local/bin/gsed -f /Users/scott/bin/conv_to_webarchive.sed | /usr/local/bin/gsed 's/\\n//g' | /usr/local/bin/gsed 's/\\t//g' | /usr/local/bin/gsed 's/\\//g' > /tmp/"$article_title".html
# Prepend metadata to file
/usr/local/bin/gsed "1i <h1>$article_title</h1>\n<h2>$article_author</h2>\n<h2>$article_date</h2>\n<h2>$article_url</h2>\n" /tmp/"$article_title".html > /tmp/"$article_title"_1.html && mv /tmp/"$article_title"_1.html /tmp/"$article_title".html
# Prepend HTML metadata to file
/usr/local/bin/gsed "1i <!DOCTYPE html>\n<html>\n<head>\n<meta charset="UTF-8">\n<title>$article_title</title>\n</head>\n<body>\n" /tmp/"$article_title".html > /tmp/"$article_title"_1.html && mv /tmp/"$article_title"_1.html /tmp/"$article_title".html
# Append HTML metadata to file
echo "</body></html" >> /tmp/"$article_title".html
# Using the webarchiver tool I downloaded & compiled, create a webarchive
if webarchiver -url /tmp/"$article_title".html -output $devonthink_dir/"$article_title".webarchive ; then
# If it works, then delete the file
rm $i
else
# Couldn’t create a webarchive
terminal-notifier -message "No webarchive for $i" -title "Problem creating webarchive"
fi
else
# If results.json can’t be renamed, move it!
mv $i $fail_safe_dir
fi
fi
else
# If Diffbot fails, move it!
mv $i $fail_safe_dir
terminal-notifier -message "Could not Diffbot $i" -title "Problem with Diffbot"
fi
else
# If it’s empty, move it!
terminal-notifier -message "$i is empty!" -title "Problem with parsing file"
mv $i $fail_safe_dir
fi
done
else
# Needed directory isn’t there, which is weird
/usr/local/bin/gecho -e "\nIncoming DevonThink directory is missing for $i!" >> "$fail_safe_dir/DEVONthink Problem.txt"
fi
# Restore IFS so it’s back to splitting on <space><tab><newline>
IFS=$SAVEIFS
else
# Needed directories aren’t there, which is very bad
/usr/local/bin/gecho -e "\nIncoming or DevonThink directories are missing for $i!" >> "$fail_safe_dir/DEVONthink Problem.txt"
fi
exit 0Note the following about the script:
-
Make sure the variables are correct for your setup.
-
In particular, you’ll need to enter your Diffbot Developer Token for
diffbot_token. And no, that’s not mine. I randomly generated a lookalike. -
The paths that start with
/Users/are all for my Mac. You’ll need to change them for yours. -
You might notice that I encode URLs in the middle; in other words, I turn
http://www.chainsawonatireswing.com/intohttp%3A%2F%2Fwww.chainsawonatireswing.com%2F. This is what Diffbot wants, so it is what Diffbot gets. -
It’s pretty easy to test and make sure you’re getting the right results from Diffbot. Just use the line from the script:
curl "http://www.diffbot.com/api/article?token=$diffbot_token&url=$encoded_url&html&timeout=20000" | /usr/local/bin/jsonpp, but put in your Diffbot Developer Token instead of$diffbot_token& the encoded URL you want to test instead of$encoded_url. By piping the output tojsonpp, you get readable results. -
Yes, I use
sed(actuallygsed) a lot. I refer to a file namedconv_to_webarchive.seda few times. That file is detailed in the next section. -
You don’t need the lines with
gecho, but I found them very useful while I was developing & testing the script, & they don’t do any harm, so I left them. If they bother you, take ’em out. -
Notice the lines that say
mv $i $fail_safe_dir. All are fail-safes in case files can’t be renamed or parsed. This became critical when I did not have them in place, & one night a file got stuck trying Diffbot repeatedly, so that I racked up 15,000 queries or so in just a few hours. Fortunately, I shamefacedly explained what happened to Diffbot support, & they very kindly forgave me. And then I immediately put in place those fail-safes, as I should have from the beginning. So if you see files on your desktop, look in them, as they indicate problems that you need to fix by hand.
The sed file
In my shell script I refer to conv_to_webarchive.sed a number of times. If you don’t know what sed is, it’s basically a way to edit files programmatically from the command line. It’s also very cool & does a million things, most of which I know nothing about (although I’d love to learn!).
Here’s the contents of conv_to_webarchive.sed:
s/\\u0092/’/g
s/\\u0093/“/g
s/\\u0094/”/g
s/\\u0097/—/g
s/\\u2013/–/g
s/\\u2014/—/g
s/\\u2018/‘/g
s/\\u2019/’/g
s/\\u201C/“/g
s/\\u201c/“/g
s/\\u201D/”/g
s/\\u201d/”/g
s/\\u2020/†/g
s/\\u2021/‡/g
s/\\u2022/•/g
s/\\u2026/…/g
s/\\u2033/"/g
I have built this file up over time, as I have found errors in the results generated by Diffbot & the other programs. Basically, Diffbot stuck the encoding for a character in the results, & I want the actual character itself. So, for instance, instead of an ellipses, I saw \u2026 in the file; my sed file turns \u2026 back into … so that it’s readable. As I discover more, I’ll add to the file.
Hazel
So we have a shell script that processes files, but how do we tell the shell script to run? Enter Hazel. Basically, Hazel watches the folders you tell it to watch, & when something changes in those folders, Hazel processes the files according to the rules you specify.
In this case, we’re going to tell Hazel to watch the Incoming/DEVONthink folder, & when a file is placed inside, the shell script detailed above should run, processing the file. Lather, rinse, repeat.
Open Hazel. On the Folders tab, press the + under Folders to add a new folder. Select ~/Dropbox/Incoming/DEVONthink.
Under Rules, press the + to add a new rule. A sheet will open, named for the folder; in this case, DEVONthink.
For a Name, I chose Convert URL to DEVONthink webarchive.
Now you need to make selections so that the following instructions are mirrored in Hazel.
If all of the following conditions are met:
Extensionistxt
Do the following:
Run shell script- Choose Other… & select
~/bin/conv_to_webarchive.sh
Press OK to close the sheet, & then close Hazel.
Test
To test your work, email a URL to trigger@ifttt.com with #dt in the subject. A few seconds later, you should see a new entry appear in your DEVONthink Inbox, stripped of extraneous formatting & info thanks to Diffbot.
In subsequent posts, I’m going to tell how to automate emailing that URL using Keyboard Maestro on the Mac & Mr. Reader & other apps on your iOS devices. I could do it here, but this post is long enough already! And even without that info, I still find this process I’ve detailed here to be incredibly useful, so much so that I use it at least 10 times a day to save webpages into DEVONthink. I hope you find it useful too!
-
Now, Diffbot normally does a great job, but not always. In those cases, you need to go to the Custom API Toolkit & tell Diffbot what to do, based on CSS selectors. I’ve been collecting materials for a long post about this that I’ll put up on this site later. ↩
-
Note that this is maybe the second time in my life I’ve messed around with Xcode, so if there’s a better way to do what I did, please let me know. ↩